
Contributors: Gabriel Antoniu, Joshua Bowden
Scientific simulation is increasingly using Artificial Intelligence (AI) to analyze data, the volume of which continues to grow, requiring more and more High-Performance Computing (HPC) resources. However, it is difficult to organize this Big Data-IA-HPC triptych because of the tangle of different software stacks in these different fields. Funded by the EuroHPC Research and Innovation program, the ACROSS project aims to build a convergence platform and develop mechanisms capable of managing such complex inter-stack flows on scales previously unknown. One of Inria’s contributions to the project is called Damaris: an innovative middleware designed for managing data input/output and processing at extreme scales.
Capturing carbon dioxide
The ACROSS project itself is organized around three use cases. The first aims to combine artificial intelligence with traditional multi-physics approaches in the field of aeronautical engine simulation. The second is the use of hardware accelerators to increase the processing speed of large-scale weather analysis. The third is about carbon dioxide sequestration. In other words, trying to capture CO2 before it is released into the atmosphere by storing it, for example underground in old oil wells. “This is the use case that Inria will focus on. It requires the development of workflows between different software stacks to perform high-precision subsurface simulation and analyze large volumes of seismic data.”
The core contribution from Inria in this project is Damaris, a middleware program designed to improve data and input/output management. Its main goal is to reduce the load on the computer during the data writing phase. With machines where sometimes a million cores find themselves writing data to a million files in a quasi-synchronous way at each iteration, the pressure on the storage system becomes too great. Computing slows down because the cores have to wait for all the data to be written before starting the next iteration. The solution with Damaris is to specialize some cores only for writing while the others continue to perform only computation. This approach allows a much better scaling. The icing on the cake is that the resource allocated to writing can also be used for something else. “In the past, we used it to visualize the data during the simulation as well. Now, we want to exploit it to perform in-situ analysis using machine learning.” In this scenario, the output data would be directed to a machine learning procedure as it is generated.
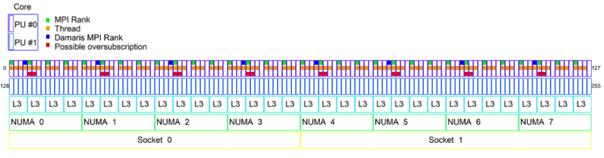
(The tool is available as a docker image https://gitlab.inria.fr/Damaris/damaris/container_registry/1161 .)
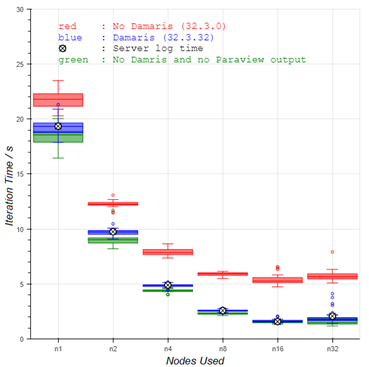
This post is an abridged, translated version of an article published in French, available here: https://project.inria.fr/emergences/convergence-big-data-ia-hpc-au-seuil-exaflopique/.
LINKS:
https://team.inria.fr/keradata/gabriel-antoniu/