
With the breakdown of Dennard scaling and the approaching of the post-Moore era, general-purpose processors can no longer sustain the complexity, variety, and computational demand of modern High-Performance Computing applications. Legacy codes are more and more often adapted to exploit hardware accelerators for running their most compute-intensive portions, while new applications are developed with native support for heterogeneous hardware, e.g. General Purpose GPUs, FPGAs, specialized ASICs, with a look at upcoming neuromorphic and Quantum accelerators. For their part, data centres are becoming increasingly modular, with diverse sets of racks equipped with different hardware technologies and optimized for different families of applications.
At the same time, the ubiquity and pervasiveness of technological devices, the value of Big Data as strategic assets, and the strict rules regulating data privacy and protection foster a Near Data Processing approach. Indeed, moving computation is often much easier and cheaper than moving data. Still, there are situations where data transfers between different modules of a complex application are worthwhile or even unavoidable. Consider, for example, the use of node-local burst buffers to reduce file-system pressure in modern HPC facilities or the edge-to-cloud data flows of IoT workloads. In those cases, data movements should be traceable, secure, reliable, and fast.
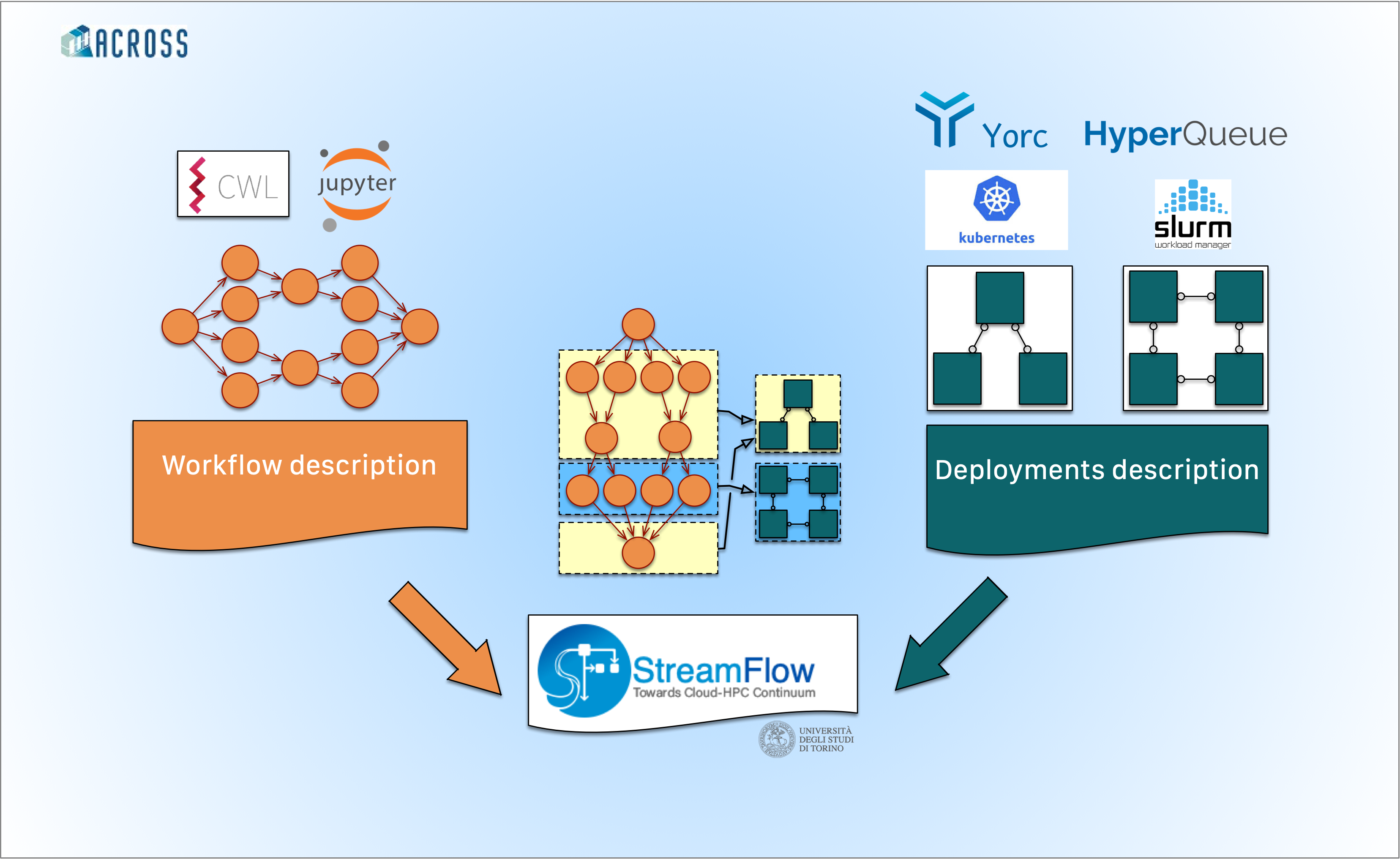
Workflow models emerge as a key paradigm to describe and implement complex distributed applications. The loose coupling between different workflow steps fosters modularity, generality, and reusability. At the same time, the explicit modelling of (data) dependencies between subsequent steps gives a clear view of the whole information flow and allows for concurrent execution of independent modules, improving performances. Still, traditional workflow systems either require a central file system for data sharing, failing to address fully distributed environments with independent executors (e.g. mixed Cloud-HPC configurations), or delegate to external schedulers (e.g. HTCondor) the data transfer management, requiring users to configure the execution environment a priori.
The ACROSS project addresses these limitations by introducing a new paradigm, called hybrid workflow, and implementing a novel orchestration architecture capable of executing it. A hybrid workflow is generally defined as a workflow whose steps can span multiple, heterogeneous, and independent computing infrastructures. Support for multiple infrastructures implies that each step must potentially target a different deployment location in charge of executing it. Locations can be heterogeneous, hosting different hardware accelerators and exposing different protocols for authentication, communication, resource allocation and job execution. Plus, they can be independent of each other, and direct communications and data transfers among them may not be allowed. A suitable model for hybrid workflows must then be composite, enclosing a specification of the workflow dependencies, a topology of the involved locations, and a mapping relation between steps and locations.
The StreamFlow framework, developed by the University of Torino, has been created as runtime support for hybrid workflows. In particular, it adopts the Common Workflow Language (CWL) open standard to express steps and dependencies and relies on many external, platform-dependent description formats to specify locations in charge of executing them (e.g. SBATCH files for Slurm workloads or Helm Charts for Kubernetes deployments). Finally, a declarative configuration file specifies mappings of steps onto locations. StreamFlow is then capable of automatically instantiating and shutting down execution environments, performing secure data transfers, offloading commands for remote executions, scheduling tasks and recovering from failures. Plus, the modular implementation of StreamFlow allows users to easily substitute each of its building blocks with a custom one and support additional workflow modelling paradigms (e.g. distributed literate workflows expressed as Jupyter Notebooks).
In ACROSS, a novel orchestration architecture will provide a consistent way to manage hybrid workflows in large-scale heterogeneous scenarios. An integration between StreamFlow and the Ystia Suite will give users a unique TOSCA-based interface to model complex Cloud-HPC execution environments for their workflows. The HyperQueue will provide a unified and efficient way of submitting tasks on sub-node level. Finally, the WARP orchestrator will rely on AI techniques to maximize global resource utilization and optimize the scheduling of concurrent hybrid workflows.